एक कुशल और सफल प्रोग्रामर बनने का मार्ग कठिन है, लेकिन एक ऐसा जो निश्चित रूप से प्राप्त किया जा सकता है। डेटा संरचना एक मुख्य घटक है जिसे प्रत्येक प्रोग्रामिंग छात्र को मास्टर करना चाहिए, और संभावना है कि आप पहले से ही कुछ बुनियादी डेटा संरचनाओं जैसे कि सरणियों या सूचियों के साथ सीख चुके हैं या काम कर चुके हैं।
साक्षात्कारकर्ता डेटा संरचनाओं से संबंधित प्रश्न पूछना पसंद करते हैं, इसलिए यदि आप नौकरी के लिए साक्षात्कार की तैयारी कर रहे हैं, तो आपको अपने डेटा संरचना ज्ञान पर ब्रश करने की आवश्यकता होगी। आगे पढ़ें क्योंकि हम प्रोग्रामर और नौकरी के साक्षात्कार के लिए सबसे महत्वपूर्ण डेटा संरचनाओं को सूचीबद्ध करते हैं।
लिंक्ड सूचियाँ सबसे बुनियादी डेटा संरचनाओं में से एक हैं और अक्सर अधिकांश डेटा संरचना पाठ्यक्रमों में छात्रों के लिए शुरुआती बिंदु होती हैं। लिंक्ड सूचियां रैखिक डेटा संरचनाएं हैं जो अनुक्रमिक डेटा एक्सेस की अनुमति देती हैं।
लिंक की गई सूची के तत्वों को अलग-अलग नोड्स में संग्रहीत किया जाता है जो पॉइंटर्स का उपयोग करके जुड़े (जुड़े) होते हैं। आप एक लिंक की गई सूची को विभिन्न बिंदुओं के माध्यम से एक दूसरे से जुड़े नोड्स की श्रृंखला के रूप में सोच सकते हैं।
सम्बंधित: जावा में लिंक्ड सूचियों का उपयोग करने का परिचय
इससे पहले कि हम विभिन्न प्रकार की लिंक्ड सूचियों की बारीकियों में उतरें, व्यक्तिगत नोड की संरचना और कार्यान्वयन को समझना महत्वपूर्ण है। लिंक की गई सूची में प्रत्येक नोड में कम से कम एक पॉइंटर होता है (डबल लिंक्ड लिस्ट नोड्स में दो पॉइंटर्स होते हैं) जो इसे सूची में अगले नोड और डेटा आइटम से जोड़ता है।
प्रत्येक लिंक की गई सूची में एक हेड और टेल नोड होता है। सिंगल-लिंक्ड लिस्ट नोड्स में केवल एक पॉइंटर होता है जो चेन में अगले नोड की ओर इशारा करता है। अगले पॉइंटर के अलावा, डबल लिंक्ड लिस्ट नोड्स में एक और पॉइंटर होता है जो चेन में पिछले नोड की ओर इशारा करता है।
लिंक्ड सूचियों से संबंधित साक्षात्कार प्रश्न आमतौर पर किसी विशिष्ट तत्व को सम्मिलित करने, खोजने या हटाने के इर्द-गिर्द घूमते हैं। किसी लिंक की गई सूची में सम्मिलित करने में O(1) समय लगता है, लेकिन सबसे खराब स्थिति में हटाने और खोजने में O(n) समय लग सकता है। तो लिंक्ड सूचियां आदर्श नहीं हैं।
2. बाइनरी ट्री
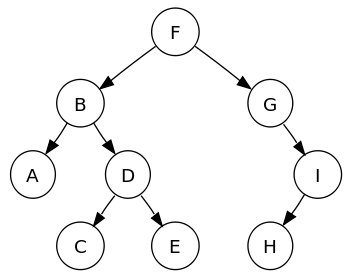
बाइनरी ट्री ट्री परिवार डेटा संरचना का सबसे लोकप्रिय उपसमुच्चय है; बाइनरी ट्री में तत्वों को एक पदानुक्रम में व्यवस्थित किया जाता है। अन्य प्रकार के पेड़ों में एवीएल, लाल-काले, बी पेड़ आदि शामिल हैं। बाइनरी ट्री के नोड्स में प्रत्येक चाइल्ड नोड के लिए डेटा तत्व और दो पॉइंटर्स होते हैं।
एक बाइनरी ट्री में प्रत्येक पैरेंट नोड में अधिकतम दो चाइल्ड नोड हो सकते हैं, और प्रत्येक चाइल्ड नोड, बदले में, दो नोड्स के लिए एक पैरेंट हो सकता है।
सम्बंधित: बाइनरी ट्री के लिए एक शुरुआती गाइड
एक बाइनरी सर्च ट्री (BST) डेटा को एक क्रमबद्ध क्रम में संग्रहीत करता है, जहाँ एक कुंजी-मान वाले तत्व माता-पिता से कम होते हैं नोड को बाईं ओर संग्रहीत किया जाता है, और मूल नोड से अधिक कुंजी-मान वाले तत्वों को संग्रहीत किया जाता है अधिकार।
बाइनरी ट्री आमतौर पर साक्षात्कार में पूछे जाते हैं, इसलिए यदि आप एक साक्षात्कार के लिए तैयार हो रहे हैं, तो आपको पता होना चाहिए कि बाइनरी ट्री को कैसे समतल करना है, एक विशिष्ट तत्व को देखना है, और बहुत कुछ।
3. हैश टेबल
हैश टेबल या हैश मैप एक अत्यधिक कुशल डेटा संरचना है जो डेटा को एक सरणी प्रारूप में संग्रहीत करता है। प्रत्येक डेटा तत्व को हैश तालिका में एक अद्वितीय अनुक्रमणिका मान दिया जाता है, जो कुशल खोज और विलोपन की अनुमति देता है।
हैश मैप में कुंजियों को निर्दिष्ट या मैप करने की प्रक्रिया को हैशिंग कहा जाता है। हैश फ़ंक्शन जितना अधिक कुशल होगा, हैश तालिका की दक्षता उतनी ही बेहतर होगी।
प्रत्येक हैश तालिका डेटा तत्वों को एक मूल्य-सूचकांक जोड़ी में संग्रहीत करती है।
जहां मूल्य डेटा संग्रहीत किया जाना है, और अनुक्रमणिका अद्वितीय पूर्णांक है जिसका उपयोग तालिका में तत्व को मैप करने के लिए किया जाता है। हैश फ़ंक्शन बहुत जटिल या बहुत सरल हो सकते हैं, यह हैश तालिका की आवश्यक दक्षता पर निर्भर करता है और आप टकरावों को कैसे हल करेंगे।
टकराव अक्सर तब होता है जब एक हैश फ़ंक्शन विभिन्न तत्वों के लिए समान मैपिंग उत्पन्न करता है; ओपन एड्रेसिंग या चेनिंग का उपयोग करके हैश मैप टकराव को अलग-अलग तरीकों से हल किया जा सकता है।
हैश टेबल या हैश मैप में क्रिप्टोग्राफी सहित विभिन्न प्रकार के विभिन्न अनुप्रयोग होते हैं। जब निरंतर ओ (1) समय में सम्मिलन या खोज करना आवश्यक होता है तो वे पहली पसंद डेटा संरचना होती हैं।
4. ढेर
ढेर सरल डेटा संरचनाओं में से एक हैं और मास्टर करने के लिए बहुत आसान हैं। एक स्टैक डेटा संरचना अनिवार्य रूप से कोई वास्तविक जीवन स्टैक (बक्से या प्लेटों के ढेर के बारे में सोचें) है और एक LIFO (लास्ट इन फर्स्ट आउट) तरीके से संचालित होता है।
स्टैक्स की LIFO प्रॉपर्टी का मतलब है कि आपके द्वारा आखिरी बार डाला गया तत्व पहले एक्सेस किया जाएगा। आप स्टैक में शीर्ष तत्व के नीचे के तत्वों को उसके ऊपर के तत्वों को पॉप किए बिना एक्सेस नहीं कर सकते।
स्टैक के दो प्राथमिक ऑपरेशन हैं- पुश और पॉप। पुश का उपयोग स्टैक में तत्व डालने के लिए किया जाता है, और पॉप स्टैक से सबसे ऊपरी तत्व को हटा देता है।
उनके पास बहुत सारे उपयोगी अनुप्रयोग भी हैं, इसलिए साक्षात्कारकर्ताओं के लिए स्टैक से संबंधित प्रश्न पूछना बहुत आम है। यह जानना कि स्टैक को कैसे उलटना है और भावों का मूल्यांकन करना काफी आवश्यक है।
5. कतारों
कतारें स्टैक के समान होती हैं लेकिन फीफो (फर्स्ट इन फर्स्ट आउट) तरीके से संचालित होती हैं, जिसका अर्थ है कि आप उन तत्वों तक पहुंच सकते हैं जिन्हें आपने पहले डाला था। कतार डेटा संरचना को किसी भी वास्तविक जीवन कतार के रूप में देखा जा सकता है, जहां लोगों को उनके आगमन के क्रम के आधार पर तैनात किया जाता है।
कतार के सम्मिलन संचालन को एनक्यू कहा जाता है, और कतार की शुरुआत से किसी तत्व को हटाने / हटाने को डीक्यूइंग कहा जाता है।
सम्बंधित: कतारों और प्राथमिकता वाली कतारों को समझने के लिए एक शुरुआती मार्गदर्शिका
सीपीयू शेड्यूलिंग जैसे कई महत्वपूर्ण अनुप्रयोगों में प्राथमिकता कतारें कतारों का एक अभिन्न अनुप्रयोग हैं। प्राथमिकता कतार में, तत्वों को आगमन के क्रम के बजाय उनकी प्राथमिकता के अनुसार क्रमबद्ध किया जाता है।
6. ढेर
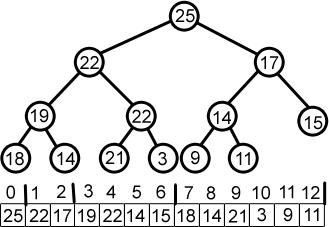
ढेर एक प्रकार का बाइनरी ट्री है जहां नोड्स को आरोही या अवरोही क्रम में व्यवस्थित किया जाता है। मिन हीप में, माता-पिता का मुख्य मूल्य उसके बच्चों के बराबर या उससे कम होता है, और रूट नोड में पूरे ढेर का न्यूनतम मूल्य होता है।
इसी तरह, मैक्स हीप के रूट नोड में हीप का अधिकतम कुंजी मान होता है; आपको पूरे ढेर में न्यूनतम/अधिकतम हीप संपत्ति को बनाए रखना होगा।
सम्बंधित: ढेर बनाम। ढेर: क्या उन्हें अलग करता है?
हीप्स के पास बहुत ही कुशल प्रकृति के कारण बहुत सारे अनुप्रयोग हैं; मुख्य रूप से, प्राथमिकता कतारों को अक्सर ढेर के माध्यम से लागू किया जाता है। वे हीपसॉर्ट एल्गोरिदम में एक मुख्य घटक भी हैं।
डेटा संरचनाएं सीखें
डेटा संरचनाएं पहली बार में कष्टप्रद लग सकती हैं, लेकिन पर्याप्त समय दें, और आप उन्हें पाई के रूप में आसान पाएंगे।
वे प्रोग्रामिंग का एक महत्वपूर्ण हिस्सा हैं, और लगभग हर परियोजना के लिए आपको उनका उपयोग करने की आवश्यकता होगी। किसी दिए गए परिदृश्य के लिए कौन सी डेटा संरचना आदर्श है, यह जानना महत्वपूर्ण है।
ये एल्गोरिदम प्रत्येक प्रोग्रामर के वर्कफ़्लो के लिए आवश्यक हैं।
आगे पढ़िए
- प्रोग्रामिंग
- डेटा विश्लेषण
- कोडिंग युक्तियाँ

फहद MakeUseOf में लेखक हैं और वर्तमान में कंप्यूटर साइंस में पढ़ाई कर रहे हैं। एक उत्साही तकनीकी-लेखक के रूप में वह सुनिश्चित करता है कि वह नवीनतम तकनीक से अपडेट रहे। वह खुद को विशेष रूप से फुटबॉल और प्रौद्योगिकी में रुचि रखता है।
हमारे न्यूज़लेटर की सदस्यता लें
तकनीकी युक्तियों, समीक्षाओं, निःशुल्क ई-पुस्तकों और अनन्य सौदों के लिए हमारे न्यूज़लेटर से जुड़ें!
सब्सक्राइब करने के लिए यहां क्लिक करें