विज्ञापन
क्या आप इस विचार में विश्वास करते हैं कि एक बार इंटरनेट पर कुछ प्रकाशित होने के बाद, यह हमेशा के लिए प्रकाशित हो जाता है? खैर, आज हम उस मिथक को दूर करने जा रहे हैं।
सच्चाई यह है कि कई मामलों में इंटरनेट से सूचनाओं का उन्मूलन संभव है। यदि आप खोज करते हैं, तो निश्चित रूप से, वेब पेजों का एक रिकॉर्ड नष्ट हो गया है वेबैक मशीन, सही? हाँ, बिल्कुल। वेबैक मशीन पर कई वर्षों से वापस जा रहे वेब पृष्ठों के रिकॉर्ड हैं - वे पृष्ठ जिन्हें आपने Google खोज के साथ नहीं पाया है क्योंकि वेब पेज अब मौजूद नहीं है। किसी ने इसे हटा दिया, या वेबसाइट बंद हो गई।
तो, इसके आस-पास कोई नहीं है, है ना? सूचनाओं को इंटरनेट के पत्थर में हमेशा के लिए उकेरा जाएगा, वहाँ पीढ़ियों को देखना है? खैर, बिल्कुल नहीं।
सच्चाई यह है कि जहां एक समाचार वेबसाइट या ब्लॉग से वायरस की तरह फैलने वाली प्रमुख समाचारों को मिटा देना मुश्किल या असंभव हो सकता है, यह वास्तव में पूरी तरह से एक वेब पेज या अस्तित्व के सभी रिकॉर्ड से कई वेब पेजों को मिटाने के लिए काफी आसान है - दोनों खोज इंजनों के लिए और साथ ही उस पेज को हटाने के लिए वेबैक मशीन नई वेबैक मशीन आपको इंटरनेट के समय में यात्रा करने की सुविधा देती है ऐसा लगता है कि 2001 में वेबैक मशीन के लॉन्च के बाद से, साइट के मालिकों ने एलेक्सा-आधारित बैक-एंड को टॉस करने और अपने स्वयं के ओपन सोर्स कोड के साथ इसे फिर से डिज़ाइन करने का फैसला किया है। के साथ परीक्षण करने के बाद ... अधिक पढ़ें . बेशक एक पकड़ है, लेकिन हम उस तक पहुंचेंगे।
नेट से ब्लॉग पेज हटाने के 3 तरीके
पहला तरीका वह है जो अधिकांश वेबसाइट के मालिक उपयोग करते हैं, क्योंकि वे किसी भी बेहतर को नहीं जानते हैं - बस वेब पेजों को हटाना। ऐसा इसलिए हो सकता है क्योंकि आपको महसूस हुआ है कि आपके पास आपकी साइट पर डुप्लिकेट सामग्री है, या क्योंकि आपके पास एक पृष्ठ है जिसे आप खोज परिणामों में नहीं दिखाना चाहते हैं।
बस पेज को डिलीट करें
आपकी वेबसाइट से पृष्ठों को पूरी तरह से हटाने के साथ समस्या यह है कि जब से आप पृष्ठ को पहले ही स्थापित कर चुके हैं नेट, आपकी अपनी साइट के लिंक के साथ-साथ अन्य साइटों से बाहरी लिंक भी विशेष रूप से होने की संभावना है पृष्ठ। जब आप इसे हटाते हैं, तो Google तुरंत आपके उस पृष्ठ को एक गुम पृष्ठ के रूप में पहचान लेता है।
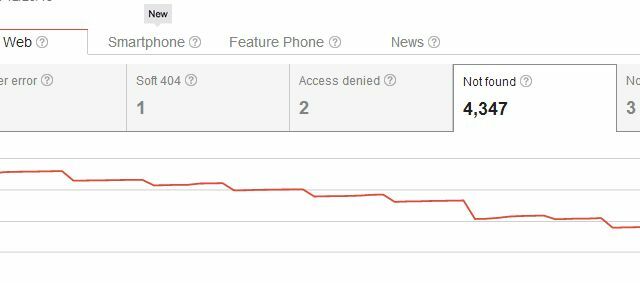
इसलिए, अपने पृष्ठ को हटाने में आपने न केवल "अपने लिए नहीं" त्रुटियों को क्रॉल किया, बल्कि आपने कभी भी उस व्यक्ति के लिए एक समस्या खड़ी कर दी, जो कभी पृष्ठ से जुड़ा हुआ है। आमतौर पर, उन बाहरी लिंक में से एक से आपकी साइट पर आने वाले उपयोगकर्ताओं को आपका 404 पृष्ठ दिखाई देगा, जो कि नहीं है बड़ी समस्या, यदि आप उपयोगकर्ताओं को उपयोगी सुझाव देने के लिए Google के कस्टम 404 कोड जैसी किसी चीज़ का उपयोग करते हैं या विकल्प। लेकिन, आपको लगता है कि मौजूदा इनकमिंग लिंक के लिए उन सभी 404 को बंद किए बिना खोज परिणामों से पृष्ठों को हटाने के अधिक सुंदर तरीके हो सकते हैं?
खैर, वहाँ हैं।
Google खोज परिणामों से एक पृष्ठ निकालें
सबसे पहले, आपको यह समझना चाहिए कि यदि आप जिस वेब पेज को Google खोज परिणामों से हटाना चाहते हैं, वह आपकी अपनी साइट का पेज नहीं है: तब तक आप भाग्य से बाहर हैं जब तक कि कानूनी कारण नहीं हैं या यदि साइट ने आपकी व्यक्तिगत जानकारी को आपके बिना ऑनलाइन पोस्ट किया है अनुमति। अगर ऐसा है, तो Google का उपयोग करें समस्या निवारण करने वाला पृष्ठ को खोज परिणामों से हटाने का अनुरोध सबमिट करने के लिए। यदि आपके पास कोई वैध मामला है, तो आपको पृष्ठ को हटाए जाने के बाद कुछ सफलता मिल सकती है - निश्चित रूप से आपको इससे भी बड़ी सफलता मिल सकती है वेबसाइट के मालिक से संपर्क करना इंटरनेट पर झूठी व्यक्तिगत जानकारी कैसे निकालेंऑनलाइन गोपनीयता की अब कोई गारंटी नहीं है। किसी वेबसाइट की रिपोर्ट करना और इंटरनेट से व्यक्तिगत जानकारी निकालना सीखें। अधिक पढ़ें जैसा कि मैंने बताया कि 2009 में वापस कैसे करें।
अब, यदि आप जिस पृष्ठ को खोज परिणामों से हटाना चाहते हैं, वह आपकी अपनी साइट पर है, तो आप भाग्य में हैं। आपको बस एक बनाने की जरूरत है robots.txt फ़ाइल करें और सुनिश्चित करें कि आपने खोज परिणामों में या तो विशिष्ट पृष्ठ को या तो अस्वीकृत नहीं किया है, या संपूर्ण निर्देशिका उस सामग्री के साथ जिसे आप अनुक्रमित नहीं करना चाहते हैं। यहाँ एक पृष्ठ को अवरुद्ध करने जैसा दिखता है।
उपभोक्ता अभिकर्ता: * Disallow: /my-deleted-article-that-i-want-removed.html
आप अपनी साइट की पूरी निर्देशिका को क्रॉल करने से बॉट्स को निम्नानुसार ब्लॉक कर सकते हैं।
उपभोक्ता अभिकर्ता: * अस्वीकार करें: / सामग्री-के बारे में व्यक्तिगत-सामान /
Google में एक उत्कृष्ट है समर्थनकारी पृष्ठ यदि आप पहले कभी नहीं बनाए हैं, तो आप robots.txt फ़ाइल बनाने में मदद कर सकते हैं। यह बहुत अच्छी तरह से काम करता है, जैसा कि मैंने हाल ही में एक लेख में बताया है संरचना सिंडिकेशन सौदों कैसे सिंडिकेशन सौदा करने के लिए और अपनी खोज रैंकिंग सुरक्षित रखेंसिंडीकेटिंग इन दिनों सभी गुस्से में है। लेकिन अचानक आप पा सकते हैं कि सिंडिकेशन पार्टनर एक कहानी के लिए खोज परिणामों में आपसे अधिक सूचीबद्ध है जिसे आपने मूल रूप से लिखा था! अपनी खोज रैंकिंग सुरक्षित रखें। अधिक पढ़ें ताकि वे आपको चोट न पहुँचाएँ (सिंडिकेशन भागीदारों से अपने पृष्ठों के अनुक्रमण को हटाने के लिए कहें जहाँ आप सिंडिकेट हैं)। एक बार जब मेरा स्वयं का सिंडिकेशन पार्टनर ऐसा करने के लिए सहमत हो गया, तो मेरे ब्लॉग से सामग्री को डुप्लिकेट करने वाले पृष्ठ पूरी तरह से खोज सूचियों से गायब हो गए।
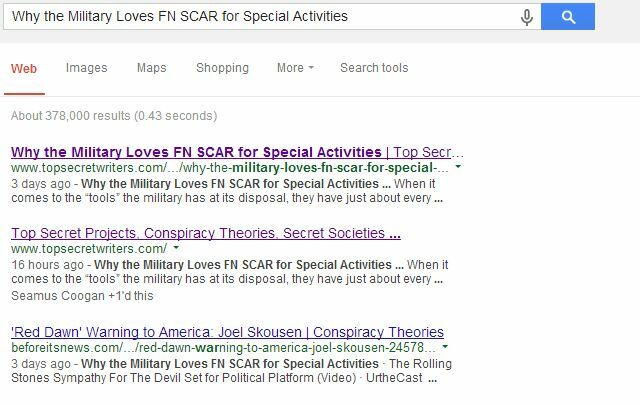
केवल मुख्य वेबसाइट उस पृष्ठ के लिए तीसरे स्थान पर आती है जहां वे हमारे शीर्षक को सूचीबद्ध करते हैं, लेकिन मेरा ब्लॉग अब पहले और दूसरे दोनों स्थानों पर सूचीबद्ध है; कुछ ऐसा है जो लगभग असंभव था एक उच्च-प्राधिकारी वेबसाइट को डुप्लिकेट किए गए पृष्ठ को छोड़ दिया गया।
बहुत से लोगों को यह एहसास नहीं है कि यह इंटरनेट पुरालेख (वेकबैक मशीन) के साथ भी पूरा करना संभव है। यहाँ लाइनें हैं जिन्हें आपको अपने robots.txt फ़ाइल में जोड़ने की आवश्यकता है ताकि यह हो सके।
उपयोगकर्ता-एजेंट: ia_archiver। अस्वीकार करें: / नमूना-श्रेणी /
इस उदाहरण में, मैं इंटरनेट आर्काइव से कह रहा हूं कि वेबैक मशीन से मेरी साइट पर नमूना-श्रेणी उपनिर्देशिका में कुछ भी हटा दें। इंटरनेट संग्रह यह बताता है कि उनके बहिष्करण सहायता पृष्ठ पर यह कैसे करना है। यह वह जगह भी है जहाँ वे समझाते हैं कि "इंटरनेट आर्काइव उन वेब साइटों या अन्य इंटरनेट दस्तावेज़ों तक पहुँच प्रदान करने में दिलचस्पी नहीं रखता है जिनके लेखक संग्रह में अपनी सामग्री नहीं चाहते हैं।"
यह आम तौर पर आयोजित विश्वास के विपरीत है कि इंटरनेट पर पोस्ट की गई सभी चीजें अनंत काल के लिए संग्रह में बह जाती हैं। नहीं - सामग्री के स्वामी वेबमास्टर्स विशेष रूप से robots.txt दृष्टिकोण का उपयोग करके संग्रह से निकाली गई सामग्री हो सकते हैं।
मेटा टैग के साथ एक व्यक्तिगत पेज निकालें
यदि आपके पास केवल कुछ व्यक्तिगत पृष्ठ हैं जिन्हें आप Google खोज परिणामों से हटाना चाहते हैं, तो आपको वास्तव में robots.txt दृष्टिकोण का उपयोग नहीं करना होगा सभी में, आप केवल सही "रोबोट" मेटा टैग को अलग-अलग पृष्ठों में जोड़ सकते हैं, और रोबोटों को पूरे सूचकांक पर अनुक्रमण या अनुसरण नहीं करने के लिए कह सकते हैं। पृष्ठ।
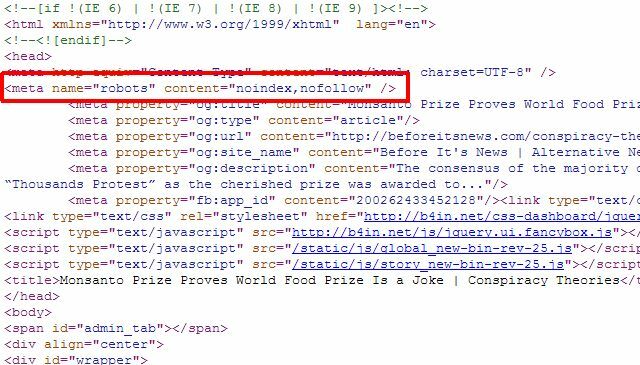
आप रोबोट को पेज को अनुक्रमित करने से रोकने के लिए ऊपर "रोबोट" मेटा का उपयोग कर सकते हैं, या आप विशेष रूप से Google रोबोट को बता सकते हैं इसलिए नहीं कि पृष्ठ को केवल Google खोज परिणामों से हटाया जाए, और अन्य खोज रोबोट अभी भी पृष्ठ तक पहुंच सकें सामग्री।
यह पूरी तरह से आप पर निर्भर करता है कि आप यह कैसे प्रबंधित करते हैं कि पेज के साथ रोबोट क्या करते हैं और पेज सूचीबद्ध होता है या नहीं। केवल कुछ अलग-अलग पृष्ठों के लिए, यह बेहतर तरीका हो सकता है। सामग्री की संपूर्ण निर्देशिका को निकालने के लिए, robots.txt विधि के साथ जाएं।
"हटाने" सामग्री का विचार
इस तरह से "इंटरनेट से सामग्री हटाने" की पूरी धारणा बदल जाती है। तकनीकी रूप से, यदि आप अपने स्वयं के लिंक को अपनी साइट के किसी पृष्ठ पर हटाते हैं, और आप इसे Google खोज और से हटा देते हैं Internet Archive, robots.txt तकनीक का उपयोग करते हुए, पेज इंटरनेट से "हटाए गए" सभी इरादों और उद्देश्यों के लिए है। हालाँकि अच्छी बात यह है कि यदि पृष्ठ पर मौजूदा लिंक हैं, तो वे लिंक अभी भी काम करेंगे और आपने उन आगंतुकों के लिए 404 त्रुटियों को ट्रिगर नहीं किया है।
इंटरनेट से आपकी साइट की मौजूदा लिंक लोकप्रियता को पूरी तरह से गड़बड़ किए बिना इंटरनेट से सामग्री को हटाने के लिए यह एक अधिक "कोमल" दृष्टिकोण है। अंत में, आप यह कैसे प्रबंधित करते हैं कि सर्च इंजन द्वारा क्या सामग्री एकत्रित की जाती है और इंटरनेट आर्काइव आपके ऊपर है, लेकिन हमेशा याद रखें कि ऑनलाइन पोस्ट होने वाली चीजों के जीवनकाल के बारे में लोग क्या कहते हैं, इसके बावजूद यह वास्तव में पूरी तरह से आपके भीतर है नियंत्रण।
रयान के पास इलेक्ट्रिकल इंजीनियरिंग में बीएससी की डिग्री है। उन्होंने ऑटोमेशन इंजीनियरिंग में 13 साल, आईटी में 5 साल काम किया है, और अब एक एप्स इंजीनियर हैं। MakeUseOf के पूर्व प्रबंध संपादक, उन्होंने डेटा विज़ुअलाइज़ेशन पर राष्ट्रीय सम्मेलनों में बात की है और इसे राष्ट्रीय टीवी और रेडियो पर चित्रित किया गया है।