विज्ञापन
अगर तुम एक वेबसाइट चलाएं ओवरकिल के बिना एक छोटी और सरल वेबसाइट बनाने के 10 तरीकेवर्डप्रेस एक ओवरकिल हो सकता है। जैसा कि ये अन्य उत्कृष्ट सेवाएं साबित करती हैं, वर्डप्रेस ही सब कुछ नहीं है और सभी वेबसाइट निर्माण का अंत है। यदि आप सरल समाधान चाहते हैं, तो चुनने के लिए विविधता है। अधिक पढ़ें , आपने शायद एक robots.txt फ़ाइल (या "रोबोट बहिष्करण मानक") के बारे में सुना होगा। आपके पास है या नहीं, इसके बारे में जानने का समय आ गया है, क्योंकि यह साधारण टेक्स्ट फ़ाइल आपकी साइट का एक महत्वपूर्ण हिस्सा है। यह महत्वहीन लग सकता है, लेकिन आपको आश्चर्य हो सकता है कि यह कितना महत्वपूर्ण है।
आइए एक नज़र डालते हैं कि robots.txt फ़ाइल क्या है, यह क्या करती है, और इसे अपनी साइट के लिए सही तरीके से कैसे सेट करें।
robots.txt फ़ाइल क्या है?
यह समझने के लिए कि robots.txt फ़ाइल कैसे काम करती है, आपको यह जानना होगा खोज इंजन के बारे में थोड़ा सा सर्च इंजन कैसे काम करते हैं?कई लोगों के लिए, Google इंटरनेट है। यकीनन यह इंटरनेट के बाद से सबसे महत्वपूर्ण आविष्कार है। और जब से खोज इंजन बहुत बदल गए हैं, अंतर्निहित सिद्धांत अभी भी वही हैं। अधिक पढ़ें
. संक्षिप्त संस्करण यह है कि वे "क्रॉलर" भेजते हैं, जो ऐसे प्रोग्राम हैं जो सूचना के लिए इंटरनेट को परिमार्जन करते हैं। फिर वे उस जानकारी में से कुछ को संग्रहीत करते हैं ताकि वे बाद में लोगों को उस पर निर्देशित कर सकें।ये क्रॉलर, जिन्हें "बॉट्स" या "स्पाइडर" के रूप में भी जाना जाता है, अरबों वेबसाइटों के पेज ढूंढते हैं। खोज इंजन उन्हें दिशा-निर्देश देते हैं कि उन्हें कहाँ जाना है, लेकिन व्यक्तिगत वेबसाइटें बॉट्स से भी संवाद कर सकती हैं और उन्हें बता सकती हैं कि उन्हें किन पृष्ठों को देखना चाहिए।
अधिकांश समय, वे वास्तव में इसके विपरीत कर रहे होते हैं, और उन्हें बता रहे होते हैं कि वे कौन से पृष्ठ हैं नहीं करना चाहिए देख रहे हो। एडमिनिस्ट्रेटिव पेज, बैकएंड पोर्टल, कैटेगरी और टैग पेज जैसी चीजें और अन्य चीजें जो साइट के मालिक सर्च इंजन पर नहीं दिखाना चाहते। ये पृष्ठ अभी भी उपयोगकर्ताओं के लिए दृश्यमान हैं, और वे किसी ऐसे व्यक्ति के लिए पहुँच योग्य हैं जिसके पास अनुमति है (जो अक्सर सभी के लिए होता है)।
लेकिन उन मकड़ियों को कुछ पृष्ठों को अनुक्रमित न करने के लिए कह कर, robots.txt फ़ाइल सभी का भला करती है। यदि आपने किसी खोज इंजन पर “मेकयूसेऑफ” की खोज की है, तो क्या आप चाहते हैं कि हमारे प्रशासनिक पृष्ठ रैंकिंग में उच्च दिखाई दें? नहीं, इससे किसी का भला नहीं होगा, इसलिए हम खोज इंजनों से कहते हैं कि उन्हें प्रदर्शित न करें। इसका उपयोग खोज इंजनों को उन पृष्ठों की जांच करने से रोकने के लिए भी किया जा सकता है जो आपकी साइट को खोज परिणामों में वर्गीकृत करने में उनकी सहायता नहीं कर सकते हैं।
संक्षेप में, robots.txt वेब क्रॉलर को बताता है कि क्या करना है।
क्या क्रॉलर robots.txt को नज़रअंदाज़ कर सकते हैं?
क्या क्रॉलर कभी robots.txt फ़ाइलों की उपेक्षा करते हैं? हां। वास्तव में, कई क्रॉलर करना को नजरअंदाज। आम तौर पर, हालांकि, वे क्रॉलर प्रतिष्ठित खोज इंजन से नहीं होते हैं। वे स्पैमर, ईमेल हार्वेस्टर, और. से हैं अन्य प्रकार के स्वचालित बॉट वेबसाइट से जानकारी खींचने के लिए एक बेसिक वेब क्रॉलर कैसे बनाएंकभी किसी वेबसाइट से जानकारी प्राप्त करना चाहते हैं? यहां बताया गया है कि किसी वेबसाइट पर नेविगेट करने के लिए क्रॉलर कैसे लिखा जाता है और आपको जो चाहिए उसे निकालता है। अधिक पढ़ें जो इंटरनेट पर घूमते हैं। इसे ध्यान में रखना जरूरी है- रोबोट को बाहर रखने के लिए रोबोट बहिष्करण मानक का उपयोग करना एक प्रभावी सुरक्षा उपाय नहीं है. वास्तव में, कुछ बॉट हो सकते हैं प्रारंभ उन पृष्ठों के साथ जिन्हें आप उन्हें नहीं जाने के लिए कहते हैं।
हालाँकि, खोज इंजन वही करेंगे जो आपकी robots.txt फ़ाइल कहती है, जब तक कि यह सही ढंग से स्वरूपित है।
robots.txt फ़ाइल कैसे लिखें
रोबोट बहिष्करण मानक फ़ाइल में कुछ भिन्न भाग होते हैं। मैं उनमें से प्रत्येक को व्यक्तिगत रूप से यहाँ तोड़ दूँगा।
उपयोगकर्ता एजेंट घोषणा
किसी बॉट को यह बताने से पहले कि उसे कौन से पृष्ठ नहीं देखने चाहिए, आपको यह निर्दिष्ट करना होगा कि आप किस बॉट से बात कर रहे हैं। अधिकांश समय, आप एक साधारण घोषणा का उपयोग करेंगे जिसका अर्थ है "सभी बॉट्स।" ऐसा दिखता है:
उपयोगकर्ता एजेंट: *तारांकन "सभी बॉट्स" के लिए है। हालाँकि, आप कुछ बॉट्स के लिए पेज निर्दिष्ट कर सकते हैं। ऐसा करने के लिए, आपको उस बॉट का नाम जानना होगा जिसके लिए आप दिशानिर्देश निर्धारित कर रहे हैं। यह इस तरह दिख सकता है:
उपयोगकर्ता-एजेंट: Googlebot. [पृष्ठों की सूची क्रॉल न करने के लिए] उपयोगकर्ता-एजेंट: Googlebot-छवि/1.0. [पृष्ठों की सूची क्रॉल न करने के लिए] उपयोगकर्ता-एजेंट: बिंगबॉट। [पृष्ठों की सूची क्रॉल न करने के लिए]और इसी तरह। यदि आपको कोई ऐसा बॉट मिलता है जिसे आप अपनी साइट को बिल्कुल भी क्रॉल नहीं करना चाहते हैं, तो आप उसे भी निर्दिष्ट कर सकते हैं।
उपयोगकर्ता एजेंटों के नाम खोजने के लिए, useragentstring.com देखें [अब उपलब्ध नहीं है]।
पृष्ठों को अस्वीकार करना
यह आपकी रोबोट बहिष्करण फ़ाइल का मुख्य भाग है। एक साधारण घोषणा के साथ, आप किसी बॉट या बॉट्स के समूह को कुछ पृष्ठों को क्रॉल न करने के लिए कहते हैं। वाक्यविन्यास आसान है। यहां बताया गया है कि आप अपनी साइट की "व्यवस्थापक" निर्देशिका में सब कुछ तक कैसे पहुंच की अनुमति नहीं देंगे:
अस्वीकृत करें: /व्यवस्थापक/वह लाइन बॉट्स को yoursite.com/admin, yoursite.com/admin/login, yoursite.com/admin/files/secret.html, और कुछ भी जो व्यवस्थापक निर्देशिका के अंतर्गत आता है, क्रॉल करने से रोकेगी।
किसी एक पृष्ठ को अस्वीकृत करने के लिए, उसे केवल अस्वीकृत पंक्ति में निर्दिष्ट करें:
अस्वीकृत करें: /public/exception.htmlअब "अपवाद" पृष्ठ नहीं खींचा जाएगा, लेकिन "सार्वजनिक" फ़ोल्डर में बाकी सब कुछ होगा।
एकाधिक निर्देशिकाओं या पृष्ठों को शामिल करने के लिए, बस उन्हें बाद की पंक्तियों में सूचीबद्ध करें:
अस्वीकार करें: /निजी/ अस्वीकृत करें: /व्यवस्थापक/ अस्वीकृत करें: /cgi-bin/ अस्वीकृत करें: /अस्थायी/वे चार पंक्तियाँ उस उपयोगकर्ता एजेंट पर लागू होंगी जिसे आपने अनुभाग के शीर्ष पर निर्दिष्ट किया है।
यदि आप बॉट्स को अपनी साइट के किसी भी पृष्ठ को देखने से रोकना चाहते हैं, तो इसका उपयोग करें:
अस्वीकार करें: /बॉट्स के लिए अलग मानक निर्धारित करना
जैसा कि हमने ऊपर देखा, आप विभिन्न बॉट्स के लिए कुछ पेज निर्दिष्ट कर सकते हैं। पिछले दो तत्वों को मिलाकर, यहाँ ऐसा दिखता है:
उपयोगकर्ता-एजेंट: googlebot. अस्वीकृत करें: /व्यवस्थापक/ अस्वीकृत करें: /निजी/उपयोगकर्ता-एजेंट: bingbot. अस्वीकृत करें: /व्यवस्थापक/ अस्वीकार करें: /निजी/ अस्वीकार करें: /गुप्त/Google और बिंग पर "व्यवस्थापक" और "निजी" अनुभाग अदृश्य होंगे, लेकिन Google "गुप्त" निर्देशिका देखेगा, जबकि बिंग नहीं करेगा।
आप तारकीय उपयोगकर्ता एजेंट का उपयोग करके सभी बॉट के लिए सामान्य नियम निर्दिष्ट कर सकते हैं, और फिर बाद के अनुभागों में भी बॉट्स को विशिष्ट निर्देश दे सकते हैं।
यह सब एक साथ डालें
ऊपर दी गई जानकारी से आप पूरी robots.txt फाइल लिख सकते हैं। बस अपने पसंदीदा टेक्स्ट एडिटर को सक्रिय करें (हम उदात्त के प्रशंसक उत्पादकता और तेज़ वर्कफ़्लो के लिए 11 शानदार टेक्स्ट टिप्सउदात्त पाठ एक बहुमुखी पाठ संपादक और कई प्रोग्रामर के लिए एक स्वर्ण मानक है। हमारे सुझाव कुशल कोडिंग पर केंद्रित हैं, लेकिन सामान्य उपयोगकर्ता कीबोर्ड शॉर्टकट की सराहना करेंगे। अधिक पढ़ें यहाँ के आसपास) और बॉट्स को यह बताना शुरू करें कि आपकी साइट के कुछ हिस्सों में उनका स्वागत नहीं है।
यदि आप robots.txt फ़ाइल का उदाहरण देखना चाहते हैं, तो बस किसी भी साइट पर जाएं और अंत में "/robots.txt" जोड़ें। ये है विशालकाय साइकिलें robots.txt फ़ाइल का हिस्सा:
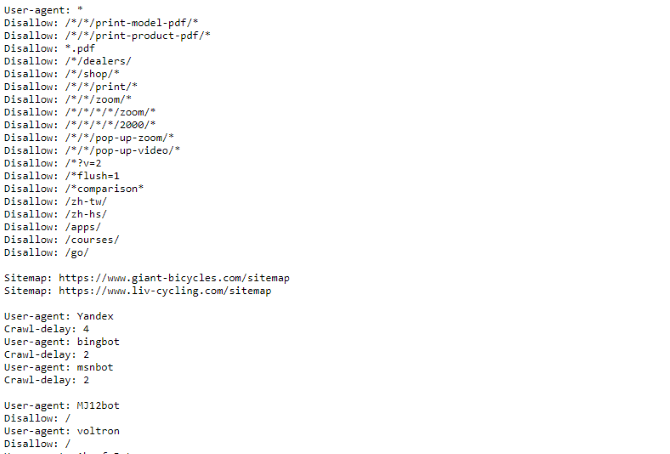
जैसा कि आप देख सकते हैं, कुछ ऐसे पृष्ठ हैं जिन्हें वे खोज इंजन पर प्रदर्शित नहीं करना चाहते हैं। उन्होंने कुछ चीजें भी शामिल की हैं जिनके बारे में हमने अभी तक बात नहीं की है। आइए देखें कि आप अपनी रोबोट बहिष्करण फ़ाइल में और क्या कर सकते हैं।
अपने साइटमैप का पता लगाना
अगर आपकी robots.txt फ़ाइल बॉट्स को बताती है कि कहाँ है नहीं जाने के लिए, तुम्हारा साइटमैप इसके विपरीत करता है 4 आसान चरणों में XML साइटमैप कैसे बनाएंसाइटमैप दो प्रकार के होते हैं - HTML पृष्ठ या XML फ़ाइल। HTML साइटमैप एक एकल पृष्ठ है जो विज़िटर को वेबसाइट के सभी पृष्ठ दिखाता है और आमतौर पर उनके लिंक होते हैं... अधिक पढ़ें , और वे जो खोज रहे हैं उसे खोजने में उनकी सहायता करते हैं। और जबकि खोज इंजन शायद पहले से ही जानते हैं कि आपका साइटमैप कहाँ है, उन्हें फिर से बताने में कोई हर्ज नहीं है।
साइटमैप स्थान के लिए घोषणा सरल है:
साइटमैप: [साइटमैप का URL]इतना ही।
हमारी अपनी robots.txt फ़ाइल में, यह इस तरह दिखता है:
साइटमैप: //www.makeuseof.com/sitemap_index.xmlयही सब है इसके लिए।
क्रॉल विलंब सेट करना
क्रॉल विलंब निर्देश कुछ खोज इंजनों को बताता है कि वे आपकी साइट पर किसी पृष्ठ को कितनी बार अनुक्रमित कर सकते हैं। इसे सेकंडों में मापा जाता है, हालांकि कुछ सर्च इंजन इसे थोड़ा अलग तरीके से समझते हैं। कुछ लोग क्रॉल में 5 सेकंड की देरी देखते हैं क्योंकि उन्हें हर क्रॉल के बाद अगले एक को शुरू करने के लिए पांच सेकंड प्रतीक्षा करने के लिए कहा जाता है। अन्य इसे हर पांच सेकंड में केवल एक पृष्ठ क्रॉल करने के निर्देश के रूप में व्याख्या करते हैं।
आप क्रॉलर को जितना संभव हो उतना क्रॉल न करने के लिए क्यों कहेंगे? प्रति बैंडविड्थ को सुरक्षित रखें 4 तरीके विंडोज 10 आपके इंटरनेट बैंडविड्थ को बर्बाद कर रहा हैक्या विंडोज 10 आपके इंटरनेट बैंडविड्थ को बर्बाद कर रहा है? यहां जांच करने का तरीका बताया गया है, और आप इसे रोकने के लिए क्या कर सकते हैं। अधिक पढ़ें . यदि आपका सर्वर ट्रैफ़िक को बनाए रखने के लिए संघर्ष कर रहा है, तो आप क्रॉल विलंब को स्थापित करना चाह सकते हैं। सामान्य तौर पर, अधिकांश लोगों को इसके बारे में चिंता करने की ज़रूरत नहीं है। हालाँकि, उच्च-ट्रैफ़िक वाली बड़ी साइटें थोड़ा प्रयोग करना चाहेंगी।
यहां बताया गया है कि आप आठ सेकंड के क्रॉल विलंब को कैसे सेट करते हैं:
क्रॉल-देरी: 8इतना ही। सभी सर्च इंजन आपके निर्देश का पालन नहीं करेंगे। लेकिन पूछने में कोई हर्ज नहीं है। पेजों को अस्वीकार करने की तरह, आप विशिष्ट खोज इंजनों के लिए अलग-अलग क्रॉल विलंब सेट कर सकते हैं।
अपनी robots.txt फ़ाइल अपलोड करना
एक बार जब आप अपनी फ़ाइल में सभी निर्देश सेट अप कर लेते हैं, तो आप इसे अपनी साइट पर अपलोड कर सकते हैं। सुनिश्चित करें कि यह एक सादा पाठ फ़ाइल है, और इसका नाम robots.txt है। फिर इसे अपनी साइट पर अपलोड करें ताकि इसे yoursite.com/robots.txt पर पाया जा सके।
यदि आप a. का उपयोग करते हैं सामग्री प्रबंधन प्रणाली 10 सबसे लोकप्रिय सामग्री प्रबंधन प्रणाली ऑनलाइनहाथ से कोड किए गए HTML पेज और CSS में महारत हासिल करने के दिन लंबे समय से चले गए हैं। एक सामग्री प्रबंधन प्रणाली (सीएमएस) स्थापित करें और मिनटों के भीतर आपके पास दुनिया के साथ साझा करने के लिए एक वेबसाइट हो सकती है। अधिक पढ़ें वर्डप्रेस की तरह, इसके बारे में जाने के लिए आपको शायद एक विशिष्ट तरीका चाहिए। चूंकि यह प्रत्येक सामग्री प्रबंधन प्रणाली में भिन्न होता है, इसलिए आपको अपने सिस्टम के दस्तावेज़ीकरण से परामर्श करने की आवश्यकता होगी।
कुछ सिस्टम में आपकी फ़ाइल अपलोड करने के लिए ऑनलाइन इंटरफेस भी हो सकते हैं। इनके लिए, बस पिछले चरणों में आपके द्वारा बनाई गई फ़ाइल को कॉपी और पेस्ट करें।
अपनी फ़ाइल को अपडेट करना याद रखें
आखिरी सलाह जो मैं दूंगा वह है कभी-कभी आपकी रोबोट बहिष्करण फ़ाइल को देखना। आपकी साइट बदल जाती है, और आपको कुछ समायोजन करने की आवश्यकता हो सकती है। यदि आप अपने खोज इंजन ट्रैफ़िक में कोई अजीब बदलाव देखते हैं, तो फ़ाइल को भी देखना एक अच्छा विचार है। यह भी संभव है कि भविष्य में मानक संकेतन बदल सकता है। आपकी साइट की अन्य सभी चीज़ों की तरह, यह समय-समय पर इसकी जाँच करने योग्य है।
आप अपनी साइट के क्रॉलर को किन पृष्ठों से बहिष्कृत करते हैं? क्या आपने सर्च इंजन ट्रैफिक में कोई अंतर देखा है? अपनी सलाह और टिप्पणियाँ नीचे साझा करें!
डैन एक कंटेंट स्ट्रैटेजी और मार्केटिंग कंसल्टेंट है जो कंपनियों को डिमांड और लीड जेनरेट करने में मदद करता है। वह dannalbright.com पर रणनीति और सामग्री विपणन के बारे में भी ब्लॉग करता है।


