विज्ञापन
वेब क्रॉलिंग वेबसाइटों पर नियमित रूप से किए गए कुछ कार्यों को स्वचालित करने के लिए अत्यंत उपयोगी है। आप एक वेबसाइट के साथ इंटरैक्ट करने के लिए क्रॉलर लिख सकते हैं जैसे कोई इंसान करता है।
में एक पूर्व लेख वेबसाइट से जानकारी खींचने के लिए एक बेसिक वेब क्रॉलर कैसे बनाएंकभी किसी वेबसाइट से जानकारी प्राप्त करना चाहते हैं? यहां बताया गया है कि किसी वेबसाइट पर नेविगेट करने के लिए क्रॉलर कैसे लिखा जाता है और आपको जो चाहिए उसे निकालता है। अधिक पढ़ें , हमने लेखन की मूल बातें कवर की हैं a वेब क्रॉलर वेब स्क्रैपिंग क्या है? वेबसाइटों से डेटा कैसे एकत्र करेंक्या आपने कभी वेब पेजों पर डेटा पढ़ने में अपना बहुमूल्य समय गंवाते हुए पाया है? यहां बताया गया है कि वेब स्क्रैपिंग के साथ आप जो डेटा चाहते हैं उसे कैसे खोजें। अधिक पढ़ें पायथन मॉड्यूल का उपयोग करके, स्क्रैपी। उस दृष्टिकोण की सीमा यह है कि क्रॉलर जावास्क्रिप्ट का समर्थन नहीं करता है। यह उन वेबसाइटों के साथ ठीक से काम नहीं करेगा जो यूजर इंटरफेस को प्रबंधित करने के लिए जावास्क्रिप्ट का भारी उपयोग करती हैं। ऐसी स्थितियों के लिए, आप एक क्रॉलर लिख सकते हैं जो Google क्रोम का उपयोग करता है और इसलिए सामान्य उपयोगकर्ता द्वारा संचालित क्रोम ब्राउज़र की तरह जावास्क्रिप्ट को संभाल सकता है।
Google क्रोम को स्वचालित करने में एक उपकरण का उपयोग शामिल है जिसे कहा जाता है सेलेनियम. यह एक सॉफ्टवेयर घटक है जो आपके प्रोग्राम और ब्राउज़र के बीच बैठता है, और आपके प्रोग्राम के माध्यम से ब्राउज़र को चलाने में आपकी सहायता करता है। इस लेख में, हम आपको Google Chrome को स्वचालित करने की पूरी प्रक्रिया से रूबरू कराते हैं। चरणों में आम तौर पर शामिल हैं:
- सेलेनियम की स्थापना
- वेबपेज के अनुभागों की पहचान करने के लिए Google क्रोम इंस्पेक्टर का उपयोग करना
- Google क्रोम को स्वचालित करने के लिए जावा प्रोग्राम लिखना
लेख के प्रयोजन के लिए, आइए देखें कि जावा से Google मेल कैसे पढ़ा जाए। जबकि Google मेल पढ़ने के लिए एक एपीआई (एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस) प्रदान करता है, इस लेख में हम प्रक्रिया को प्रदर्शित करने के लिए Google मेल के साथ बातचीत करने के लिए सेलेनियम का उपयोग करते हैं। Google मेल जावास्क्रिप्ट का भारी उपयोग करता है, और इस प्रकार सेलेनियम सीखने के लिए एक अच्छा उम्मीदवार है।
सेलेनियम की स्थापना
वेब चालक
जैसा कि ऊपर बताया गया है, सेलेनियम एक सॉफ्टवेयर घटक होता है जो एक अलग प्रक्रिया के रूप में चलता है और जावा प्रोग्राम की ओर से क्रिया करता है। इस घटक को कहा जाता है वेब चालक और आपके कंप्यूटर पर डाउनलोड होना चाहिए।
यहां क्लिक करें सेलेनियम डाउनलोड साइट पर जाने के लिए, नवीनतम रिलीज पर क्लिक करें और अपने कंप्यूटर ओएस (विंडोज, लिनक्स, या मैकोज़) के लिए उपयुक्त फ़ाइल डाउनलोड करें। यह एक ज़िप संग्रह है जिसमें chromedriver.exe. इसे किसी उपयुक्त स्थान पर निकालें जैसे कि C:\WebDrivers\chromedriver.exe. हम बाद में जावा प्रोग्राम में इस स्थान का उपयोग करेंगे।
जावा मॉड्यूल
अगला कदम सेलेनियम का उपयोग करने के लिए आवश्यक जावा मॉड्यूल स्थापित करना है। यह मानते हुए कि आप जावा प्रोग्राम बनाने के लिए मावेन का उपयोग कर रहे हैं, निम्नलिखित निर्भरता को अपने में जोड़ें पोम.एक्सएमएल.
org.seleniumhq.selenium सेलेनियम-जावा 3.8.1 जब आप बिल्ड प्रक्रिया चलाते हैं, तो सभी आवश्यक मॉड्यूल डाउनलोड किए जाने चाहिए और आपके कंप्यूटर पर सेट होने चाहिए।
सेलेनियम पहला कदम
आइए सेलेनियम के साथ शुरुआत करें। पहला कदम a. बनाना है क्रोमड्राइवर उदाहरण:
वेबड्राइवर ड्राइवर = नया क्रोमड्राइवर (); उसे एक Google क्रोम विंडो खोलनी चाहिए। आइए हम Google खोज पृष्ठ पर नेविगेट करें।
Driver.get(" http://www.google.com"); पाठ इनपुट तत्व का संदर्भ प्राप्त करें ताकि हम खोज कर सकें। टेक्स्ट इनपुट तत्व का नाम है क्यू. हम विधि का उपयोग करके पृष्ठ पर HTML तत्वों का पता लगाते हैं WebDriver.findElement ().
WebElement तत्व = Driver.findElement (By.name("q")); आप विधि का उपयोग करके किसी भी तत्व को पाठ भेज सकते हैं सेंडकी (). आइए हम एक खोज शब्द भेजें और इसे एक नई पंक्ति के साथ समाप्त करें ताकि खोज तुरंत शुरू हो।
element.sendKeys ("टर्मिनेटर \ n"); अब जब खोज चल रही है, तो हमें परिणाम पृष्ठ की प्रतीक्षा करनी होगी। हम इसे इस प्रकार कर सकते हैं:
new WebDriverWait (चालक, 10). तक (d -> d.getTitle().toLowerCase().startsWith("terminator")); यह कोड मूल रूप से सेलेनियम को 10 सेकंड तक प्रतीक्षा करने और पृष्ठ शीर्षक शुरू होने पर वापस आने के लिए कहता है टर्मिनेटर. प्रतीक्षा करने के लिए शर्त निर्दिष्ट करने के लिए हम लैम्ब्डा फ़ंक्शन का उपयोग करते हैं।
अब हम पृष्ठ का शीर्षक प्राप्त कर सकते हैं।
System.out.println ("शीर्षक:" + Driver.getTitle ()); एक बार जब आप सत्र के साथ कर लेते हैं, तो ब्राउज़र विंडो को इसके साथ बंद किया जा सकता है:
ड्राइवर। छोड़ो (); और वह, दोस्तों, सेलेनियम के माध्यम से जावा का उपयोग करके नियंत्रित एक साधारण ब्राउज़र सत्र है। काफी सरल लगता है, लेकिन आपको बहुत सी चीजों को प्रोग्राम करने में सक्षम बनाता है जो आम तौर पर आपको हाथ से करना होता है।
Google क्रोम इंस्पेक्टर का उपयोग करना
गूगल क्रोम इंस्पेक्टर क्रोम डेवलपर टूल या फ़ायरबग के साथ वेबसाइट की समस्याओं का पता लगाएंयदि आप अब तक मेरे jQuery ट्यूटोरियल का अनुसरण कर रहे हैं, तो हो सकता है कि आप पहले से ही कुछ कोड समस्याओं में भाग चुके हों और उन्हें ठीक करने का तरीका नहीं जानते हों। जब एक गैर-कार्यात्मक बिट कोड का सामना करना पड़ता है, तो यह बहुत... अधिक पढ़ें सेलेनियम के साथ उपयोग किए जाने वाले तत्वों की पहचान करने के लिए एक अमूल्य उपकरण है। यह हमें जानकारी निकालने के लिए जावा से सटीक तत्व के साथ-साथ एक बटन क्लिक करने जैसी इंटरैक्टिव क्रिया को लक्षित करने की अनुमति देता है। यहां निरीक्षक का उपयोग करने के तरीके के बारे में बताया गया है।
Google Chrome खोलें और किसी पृष्ठ पर नेविगेट करें, इसके लिए IMDb पृष्ठ कहें जस्टिस लीग (2017).
आइए हम उस तत्व को खोजें जो लक्षित करना चाहता है, जैसे कि मूवी सारांश। सारांश पर राइट क्लिक करें और पॉपअप मेनू से "निरीक्षण करें" चुनें।
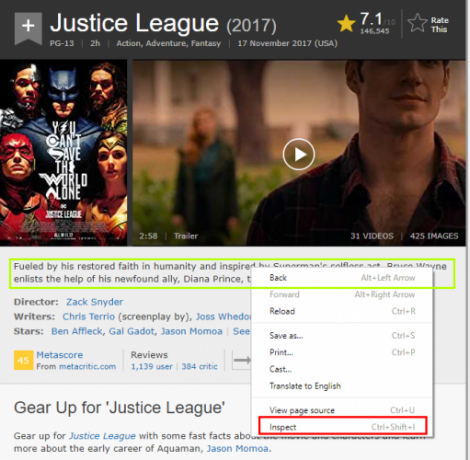
"तत्व" टैब से, हम देख सकते हैं कि सारांश पाठ एक है डिव के वर्ग के साथ सारांश_पाठ.
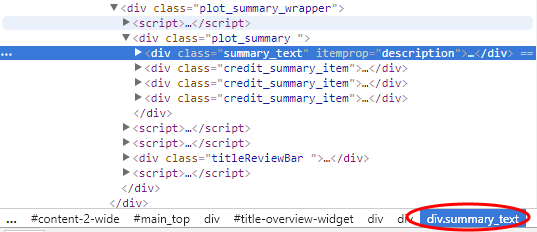
चयन के लिए CSS या XPath का उपयोग करना
सेलेनियम सीएसएस का उपयोग करके पृष्ठ से तत्वों का चयन करने का समर्थन करता है। (सीएसएस बोली समर्थित है सीएसएस 2). उदाहरण के लिए उपरोक्त IMDb पृष्ठ से सारांश पाठ का चयन करने के लिए, हम लिखेंगे:
WebElement सारांशEl = Driver.findElement (By.cssSelector("div.summary_text")); आप समान तरीके से तत्वों का चयन करने के लिए XPath का भी उपयोग कर सकते हैं (Go यहां विनिर्देशों के लिए)। फिर से, सारांश पाठ का चयन करने के लिए, हम यह करेंगे:
WebElement सारांशEl = Driver.findElement (By.xpath("//div[@class='summary_text']")); XPath और CSS में समान क्षमताएं हैं, ताकि आप अपनी सुविधानुसार किसी भी चीज़ का उपयोग कर सकें।
जावा से Google मेल पढ़ना
आइए अब एक अधिक जटिल उदाहरण देखें: Google मेल प्राप्त करना।
Chrome ड्राइवर प्रारंभ करें, gmail.com पर नेविगेट करें और पृष्ठ लोड होने तक प्रतीक्षा करें।
वेबड्राइवर ड्राइवर = नया क्रोमड्राइवर (); Driver.get(" https://gmail.com"); new WebDriverWait (ड्राइवर, 10) .until (d -> d.getTitle().toLowerCase().startsWith("gmail")); इसके बाद, ईमेल फ़ील्ड देखें (इसे आईडी के साथ नाम दिया गया है पहचानकर्ता आईडी) और ईमेल पता दर्ज करें। दबाएं अगला बटन और पासवर्ड पेज लोड होने की प्रतीक्षा करें।
/* यूजरनेम/ईमेल टाइप करें */ {driver.findElement (By.cssSelector("#identifierId")).sendKeys (ईमेल); Driver.findElement (By.cssSelector(.RveJvd”)).क्लिक करें (); } नया WebDriverWait (चालक, 10). तक (d ->! d.findElements (By.xpath("//div[@id='password']")).isEmpty() );अब, हम पासवर्ड दर्ज करते हैं, क्लिक करें अगला फिर से बटन दबाएं और जीमेल पेज के लोड होने की प्रतीक्षा करें।
/* पासवर्ड टाइप करें */ { ड्राइवर .findElement (By.xpath("//div[@id='password']//input[@type='password']")) .sendKeys (पासवर्ड); Driver.findElement (By.cssSelector(.RveJvd”)).क्लिक करें (); } नया WebDriverWait (चालक, 10). तक (d ->! d.findElements (By.xpath("//div[@class='Cp']")).isEmpty() );प्रत्येक प्रविष्टि पर ईमेल पंक्तियों और लूप की सूची प्राप्त करें।
सूचीपंक्तियाँ = ड्राइवर .findElements (By.xpath("//div[@class='Cp']//table/tbody/tr")); के लिए (WebElement tr: पंक्तियाँ) { } प्रत्येक प्रविष्टि के लिए, प्राप्त करें से खेत। ध्यान दें कि कुछ From प्रविष्टियों में बातचीत में लोगों की संख्या के आधार पर कई तत्व हो सकते हैं।
{/* तत्व से */ System.out.println ("प्रेषक:"); for (WebElement e: tr .findElements (By.xpath(.//div[@class='yW']/*"))) {System.out.println(" " + e.getAttribute("email") + "," + e.getAttribute ("नाम") + "," + e.getText ()); } }अब, विषय लाओ।
{/* विषय */ System.out.println ("उप:" + tr.findElement (By.xpath(.//div[@class='yNN']")).getText()); }
और संदेश की तारीख और समय।
{/* दिनांक/समय */ WebElement dt = tr.findElement (By.xpath(./td[8]/*")); System.out.println ("दिनांक:" + dt.getAttribute ("शीर्षक") + "," + dt.getText ()); }
यहाँ पृष्ठ में ईमेल पंक्तियों की कुल संख्या है।
System.out.println (rows.size() + "mails."); और अंत में, हम कर चुके हैं इसलिए हमने ब्राउज़र छोड़ दिया।
ड्राइवर। छोड़ो (); संक्षेप में, आप उन वेबसाइटों को क्रॉल करने के लिए Google क्रोम के साथ सेलेनियम का उपयोग कर सकते हैं जो जावास्क्रिप्ट का अत्यधिक उपयोग करती हैं। और Google क्रोम इंस्पेक्टर के साथ, किसी तत्व से निकालने या उसके साथ बातचीत करने के लिए आवश्यक सीएसएस या XPath को काम करना काफी आसान है।
क्या आपके पास सेलेनियम का उपयोग करने से लाभान्वित होने वाली कोई परियोजना है? और आप इसके साथ किन मुद्दों का सामना कर रहे हैं? कृपया नीचे टिप्पणी में वर्णन करें।

